3 Introdução ao Python 🚀
Python é uma linguagem multiparadigma, com uma sintaxe simples que permite ao utilizador focar no problema e deixar de lado qualquer tipo de especificidade. A linguagem vem sendo amplamente utilizada em diversas áreas, por conta das milhares de bibliotecas que possui, boa parte dessas distribuídas pela incrível comunidade da linguagem ❤️.
Nesta introdução, o foco será a aplicação da linguagem Python na manipulação e tratamento de dados, utilizando como base a biblioteca Pandas.
Você pode estar se perguntando o motivo da utilização desta biblioteca e a resposta é bem simples. Python é uma linguagem de uso geral, assim, suas funções nativas não tem como foco uma aplicação específica. Isso diferencia o Python de linguagens como R e Julia, que possuem áreas específicas de aplicação. Com isso, não podemos esperar que nativamente a linguagem tenha métodos variados para a manipulação e tretamento de dados e é nessa parte que o Pandas trabalha, facilitando toda a manipulação e tratamento de dados com funções incríveis.
Vamos começar !
3.1 Introdução ao Pandas 🐼
Para iniciar, vamos entender o que é a biblioteca Pandas e qual seu objetivo geral, para isso, vejamos a definição feita na documentação oficial do projeto.
Pandas é uma biblioteca open source, licenciada pelo BSD, que fornece estruturas de dados de alto desempenho e fáceis de usar e ferramentas de análise de dados para a linguagem de programação Python.
Veja então que, o Pandas possui quase tudo o que é necessário para a realização de um projeto de análise de dados na linguagem Python. Isso faz com que a biblioteca seja a principal ferramenta Python para a área de Data Science.
Para se ter uma ideia, o Pandas pode ser aplicado em análises envolvendo:
- Finanças;
- Geociências;
- Ciência social;
- Além de diversas outras áreas de ciências e engenharia.
Nos próximos tópicos serão abordadas as principais funções e estruturas de dados do Pandas, evidenciando o quão fácil é a utilização da ferramenta.
3.2 Estruturas de dados
O Pandas disponibiliza diversas estruturas de dados preparadas para o trabalho com grandes volumes de dados, sendo as principais:
- Series;
- DataFrames.
Nos subtópicos abaixo vamos ver as características de cada uma dessas estruturas, e em seguida, veremos alguns utilitários para leitura de dados com Pandas.
3.2.1 Series
As Series são estruturas unidimensionais, que contam com diversos métodos para a manipulação de dados.
Pode-se entender que as Series são estruturas de dados simples, assim como as listas padrões da linguagem Python, com uma pequena diferença, os items dentro de uma Series possuem um índice.
Para entendermos como a estrutura funciona, vamos apresentar alguns exemplos de como criar e manipular as Series.
No código abaixo, inicialmente é realizada a importação do Pandas com o ‘apelido’ de pd. Em seguida criamos uma Series simples, passando como parâmetro de entrada uma lista com três valores, veja:
## 0 1
## 1 2
## 2 3
## dtype: int64Ao fazer pd.Series, você está explicitamente informando que a estrutura de dados
Seriesestá no contexto da biblioteca Pandas.
É interessante notar que cada elemento da Series possui um índice associado. Este índice permite a recuperação rápida e simples dos dados que compõem a Series. A recuperação feita através de índices é muito parecida com a recuperação de valores em um dicionário em Python. Abaixo é apresentado um exemplo de como indexar e recuperar um elemento da Series:
## 1Através do atributo index é possível visualizar os índices associados a estrutura:
## RangeIndex(start=0, stop=3, step=1)O índice pode ser facilmente editado como segue:
## Index(['um', 'dois', 'tres'], dtype='object')Também é possível já criar uma Series com um índice personalizado, para isto, basta passar como parâmetro do construtor da Series uma segunda lista com os valores dos índices.
s = pd.Series([7, 8, 9], [1, 2, 3])
# ou
s = pd.Series([7, 8, 9], index=[1, 2, 3]) # Fica explicito quem é o índiceNote que a primeira lista passada representa os dados, e a segunda o índice.
## 1 7
## 2 8
## 3 9
## dtype: int64É possível criar uma Series através de um dicionário Python. Veja o exemplo:
## instituto INPE
## nota 10
## dtype: objectApós a construção o uso é basicamente o mesmo do dicionário. Além do que já foi dito sobre as Series, é importante lembrar que, estas estruturas de dados possuem diversos métodos para facilitar a manipulação e entendimento dos dados, apresentados nas próximas seções.
Mesmo as Series sendo estruturas de dados poderosas, elas apresentam a limitação da unidimensionalidade. Isso impede que estruturas N-dimensionais (Como por exemplo, matrizes, tabelas e similares) não possam ser facilmente representadas através das Series. Para exemplificar este impedimento, vamos inserir uma matriz de dados em uma Series, erros não serão apresentados, porém, a representação pode não ficar como desejado.
## 0 [1, 2, 3]
## 1 [4, 5, 6]
## dtype: objectPercebeu ? Não há uma matriz, e sim listas de listas associadas aos índices. A ideia é que a matriz fosse apresentada em um formato onde cada elemento está em uma posição, como na tabela abaixo.
| 1 | 2 | 3 |
| 4 | 5 | 6 |
Para estes casos é necessário o uso de uma outra estrutura de dados, o DataFrame, tratado no subtópico seguinte.
3.2.2 DataFrames
Agora que você já conhece como as Series funcionam, vamos apresentar a você o DataFrame. O DataFrame difere das Series por ser uma estrutura multidimensional, ou seja, trabalha com linhas e colunas.
Boa parte dos métodos disponíveis em uma Series também são aplicáveis em DataFrames, o que ajuda no aprendizado da utilização da API do Pandas. É importante entender que, o fato de haver mais dimensões nos dados torna a manipulação diferente, com resultados diferentes (Isto para os mesmos métodos).
Vejamos algumas características bacanas dos DataFrames:
## 0 1 2
## 0 1 2 3
## 1 4 5 6O processo acima quando realizado nas Series, gera listas de listas. Porém com os DataFrames tem-se uma matriz com formas de recuperação por linhas e colunas. Da mesma forma que as Series, os DataFrames permitem que os índices sejam (re)nomeados, além disso, as colunas também podem ser (re)nomeadas e utilizadas para a recuperação de dados.
tabela = pd.DataFrame([[.9, .8, .7], [.4, .5, .7]], columns = ['primeiro', 'segundo', 'terceiro'], index = ['zero', 'um'])
print(tabela)## primeiro segundo terceiro
## zero 0.9 0.8 0.7
## um 0.4 0.5 0.7Um DataFrame também pode ser criado através de um dicionário, veja como isso é feito:
## nome idade
## 0 felipe 12
## 1 maria 13Bem, agora que você entendeu a diferença fundamental entre essas estruturas de dados, vamos aprender sobre diferentes métodos para a manipulação dessas estruturas.
3.2.3 Seleção e filtro dos dados
Uma parte muito importante é a seleção e filtragem dos dados. Vamos começar fazendo a busca utilizando os índices (index) e as colunas (No caso dos DataFrames). Para isto, utilizamos os métodos .loc, que permitem buscar uma linha com algum nome de índice específico e o .iloc que busca uma linha em uma posição específica.
A sintaxe de utilização básica para as duas estruturas de dados podem ser vistas abaixos:
| DataFrame | Series |
|---|---|
| .loc[Nome da linha, Nome da coluna] | .loc[Nome da linha] |
| .iloc[posição da linha, posição da coluna] | .iloc[posição da linha] |
Note as diferenças de sintaxe em relação a estrutura de dados (Series ou DataFrames) adotada. Os métodos mudam pela quantidade de parâmetros que podem ser utilizados. O .loc e .iloc permitem a busca por linhas e colunas nos DataFrames e somente das linhas em uma Series.
df = pd.DataFrame({
'nome': ['Joana', 'Maria', 'Josefa'],
'idade': [15, 18, 21],
'nota': [8, 9, 10]
}, index = [7, 8, 9])
# Recuperando o nome da aluna com index 9
df.loc[9, 'nome']
# É possível também recuperar mais de uma coluna com o .loc## 'Josefa'## nome Josefa
## idade 21
## Name: 9, dtype: object## 'Josefa'## nome Josefa
## idade 21
## Name: 9, dtype: object## 18Ambas estruturas também permitem a utilização de expressões booleanas para filtragem dos dados. No exemplo abaixo é instanciado um DataFrame de valores numéricos. O objetivo é selecionar todos elementos do DataFrame maiores ou iguais a 5.
## numeros
## 4 5
## 5 6
## 6 7
## 7 8
## 8 9
## 9 10O exemplo utilizou um
DataFrame, mas as expressões booleanas também podem ser aplicadas nasSeries.
Esses são os conceitos básicos para a manipulação e filtragem dos dados. Existem diversas funções e métodos que podem ser utilizados para esse fim. Inicialmente veremos somente parte deles, porém, só com o que vimos até aqui já é possível realizar grande parte das etapas de análise de dados.
3.2.4 Agrupamento de dados e agregações
Muitas vezes quereos agrupar nossos dados para obter informações, seja para facilitar a manipulação, o entendimento das relações contidas nos dados, ou mesmo para aplicar funções sobre cada um dos grupos e obter informações a partir disto. Para isso podemos utilizar diferentes formas de agrupamentos e agregações.
O termo agregações pode apresentar diferentes definições, aqui foi assumido que, “Agregações são operações aplicadas sobre os dados que resultam em um conjunto de valores”.
No Pandas, o retorno de uma agregação pode mudar de acordo com a estrutura de dados, no caso das Series é retornado apenas um valor escalar. Para os DataFrames, o retorno da agregação é um valor para cada linha ou coluna (A dimensão pode ser definida pelo usuário).
Algumas operações de agregação são:
- sum() -> Realiza somatório;
- min() -> Busca o valor mínimo;
- max() -> Busca o valor máximo;
- count() -> Realiza a contagem de elementos.
s = pd.Series([1, 2, 3])
df = pd.DataFrame([[1, 2, 3,], [4, 5, 6]])
# Agregando Series
print(s.sum())
# Agregando DataFrame## 6## 0 5
## 1 7
## 2 9
## dtype: int64Por outro lado, as operações de agrupamento realizam a divisão dos dados em conjuntos que possuem alguma similaridade. No Pandas o agrupamento é realizado com o método groupby presente nas Series e DataFrames.
O critério de similaridade utilizado nas operações de agrupamento são definidos pelo usuário.
Aqui vamos focar no agrupamento dos DataFrames, mas os passos são os mesmos para as Series.
df = pd.DataFrame({
'nome': ['Tel1', 'Tel2', 'Tel3'],
'tipo': ['antigo', 'novo', 'novo']
})
# Etapa de divisão dos dados
agrupado = df.groupby('tipo')No exemplo acima, os dados foram agrupados de acordo com a coluna tipo. No caso, os elementos que possuem o mesmo valor do atributo tipo são agrupados por linhas.
Certo, a operação é simples e intuitiva, mas o que devemos esperar deste método ? Intuitivamente pensamos em um conjunto de DataFrames, onde cada DataFrame representa um grupo. Esse é exatamente o retorno do Pandas, porém, há algumas particulariedades. O tipo retornado de uma operação groupby deixa de ser um DataFrame e passa a ser um DataFrameGroupBy. Isso facilita a manipulação dos grupos com métodos especializados.
Vamos iniciar o entendimento do DataFrameGroupBy pela verificação dos grupos criados. Esse processo é feito através do atributo groups.
## {'antigo': Int64Index([0], dtype='int64'), 'novo': Int64Index([1, 2], dtype='int64')}Acessando o atributo groups é possível verificar todos os grupos gerados e seus membros. Além disto, com um objeto DataFrameGroupBy é possível aplicarmos os conceitos de agregação dentro dos grupos gerados pelo groupby.
Para entendermos o funcionamento do processo de agrupamento e agregação juntos, vejamos a definição feita por Hadley Wickham:
“O processo de dividir é o agrupamento, onde os dados são agrupados de acordo com alguma característica definida previamente, a aplicação realiza as agregações, filtros ou transformações e por fim a combinação, que representa a junção dos resultados das etapas anteriores”
Na definição o processo é dividido nas etapas Dividir-Aplicar-Combinar. Na figura abaixo é apresentado um fluxograma das diferentes etapas deste processo.
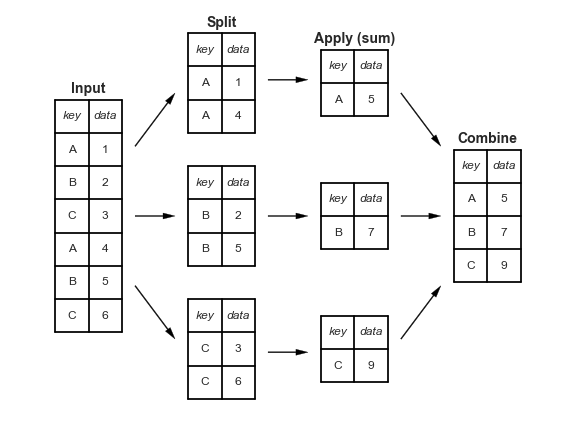
Para aprimorar o entendimento vamos criar um exemplo.
df = pd.DataFrame({
'nome': ['felipe', 'joão', 'maria', 'ana'],
'idade': [19, 19, 20, 20],
'dinheiro': [100, 100, 150, 150]
})No código apresentado abaixo é realizado um agrupamento levando em consideração o atributo idade.
# Esta é a etapa de divir, da definição do Hedley
agrupado = df.groupby('idade')
# Aplicando uma agregação
## Esta é a etapa de aplicação e junção, definida pelo Hedley
print(agrupado.count())## nome dinheiro
## idade
## 19 2 2
## 20 2 2Veja que o resultado do agrupamento apresenta o valor do atributo idade e a quantidade de elementos associados ao grupo. Mas é possível aplicar a agregação em uma coluna específica ? Sim, é possível!
## idade
## 19 200
## 20 300
## Name: dinheiro, dtype: int64Pronto! No exemplo acima é apresentado um exemplo de como agregar uma coluna específica no caso o atributo dinheiro. Com estes métodos de manipulação já é possível resolver diversos problemas do mundo real!
3.2.5 Funções de leitura e escrita de dados
Além das estruturas de dados poderosas, o pandas também possui funções para leitura e escrita de dados que facilitam muito a vida 🚀.
Como existem muitas funções para leitura e escrita, aqui serão apresentadas apenas algumas. Para conhecer outras funções de leitura e escrita não deixe de conferir a documentação do projeto.
Caso você esteja trabalhando com dados estruturados salvos em um arquivo .csv, existe a função read_csv para te ajudar.
O ponto importante a ser notado é que, os dados quando carregados com as funções do Pandas, sempre serão alocados em memória como uma Series ou DataFrame. Com a função type vamos verificar qual o tipo do dado carregado.
## <class 'pandas.core.frame.DataFrame'>Observe que o dado ao ser lido é representado como uma DataFrame. Portanto, podemos utilizar todos os métodos já vistos até aqui. Existem algumas formas de visualizar os dados carregados. A seguir são apresentados exemplos das funções head e tail que respectivamente recuperam o início e o final do DataFrame.
## PassengerId Pclass Name ... Fare Cabin Embarked
## 0 892 3 Kelly, Mr. James ... 7.8292 NaN Q
## 1 893 3 Wilkes, Mrs. James (Ellen Needs) ... 7.0000 NaN S
## 2 894 2 Myles, Mr. Thomas Francis ... 9.6875 NaN Q
## 3 895 3 Wirz, Mr. Albert ... 8.6625 NaN S
## 4 896 3 Hirvonen, Mrs. Alexander (Helga E Lindqvist) ... 12.2875 NaN S
##
## [5 rows x 11 columns]## PassengerId Pclass Name Sex ... Ticket Fare Cabin Embarked
## 413 1305 3 Spector, Mr. Woolf male ... A.5. 3236 8.0500 NaN S
## 414 1306 1 Oliva y Ocana, Dona. Fermina female ... PC 17758 108.9000 C105 C
## 415 1307 3 Saether, Mr. Simon Sivertsen male ... SOTON/O.Q. 3101262 7.2500 NaN S
## 416 1308 3 Ware, Mr. Frederick male ... 359309 8.0500 NaN S
## 417 1309 3 Peter, Master. Michael J male ... 2668 22.3583 NaN C
##
## [5 rows x 11 columns]Caso os dados que você está trabalhando sejam oriundos de algum serviço web, o Pandas também pode te ajudar! Com o método read_json você pode passar não só o nome do arquivo json em sua máquina, mas também a URL do serviço web que distribui tais dados. Como exemplo vamos recuperar dados de uma API Rest de exemplo.
json_frame = pd.read_json('http://dummy.restapiexample.com/api/v1/employees')
print(json_frame.head())## status data message
## 0 success {'id': 1, 'employee_name': 'Tiger Nixon', 'emp... Successfully! All records has been fetched.
## 1 success {'id': 2, 'employee_name': 'Garrett Winters', ... Successfully! All records has been fetched.
## 2 success {'id': 3, 'employee_name': 'Ashton Cox', 'empl... Successfully! All records has been fetched.
## 3 success {'id': 4, 'employee_name': 'Cedric Kelly', 'em... Successfully! All records has been fetched.
## 4 success {'id': 5, 'employee_name': 'Airi Satou', 'empl... Successfully! All records has been fetched.## Index(['status', 'data', 'message'], dtype='object')Da mesma forma que a leitura, fazer escrita de dados com pandas é muito simples. Tendo os dados sobre uma Series ou DataFrame é possível salvar os dados em diferentes formatos. Por exemplo, o método to_csv pode ser utilizado para salvar uma Series ou um DataFrame em um arquivo .csv.
Mas caso você queira salvar em um arquivo json, basta trocar o método to_csv para to_json e pronto! Seus dados estarão disponibilizados no sistema de arquivos nos formatos indicados.
Viu ? É tudo muito simples e direto, o que te permite focar em sua análise e deixar de lado problemas com sintaxe 🗽. Para fechar esta seção de análise de dados com Python e Pandas, será apresentado um exemplo de análise que pode ser utilizada em aplicaçẽos reais.
3.3 Exemplos
Para o exemplo foi utilizado o conjunto de dados Meteorite Landings retirados da plataforma Kaggle. O conjunto de dados consistem em mais de 45 mil registros de meteoros que atingiram a Terra.
Para iniciar a análise inicialmente importamos a biblioteca Pandas.
Depois de importar a biblioteca, faça a importação dos dados
Fazer análise de dados é responder perguntas, matar a curiosidade, então, na análise feita, algumas perguntas serão feitas para que a análise tenha algum objetivo.
Para começar, vamos verificar o tipo de dado que foi devolvido da função read_csv utilizada para carregar os dados.
## <class 'pandas.core.frame.DataFrame'>Beleza, é um DataFrame, isso indica que vamos conseguir aplicar os métodos que vimos anteriormente sem problemas. Agora vamos verificar as dimensões que a tabela representa no DataFrame possui. Para tal, o atributo shape será utilizado.
## (45716, 10)Interessante! Os valores (45716, 10), indicam respectivamente que, o conjunto de dados possui 45716 linhas e 10 colunas. Por falar nas colunas, vamos verificar quais são as colunas disponíveis neste conjunto de dados.
## Index(['name', 'id', 'nametype', 'recclass', 'mass', 'fall', 'year', 'reclat',
## 'reclong', 'GeoLocation'],
## dtype='object')A descrição de cada coluna está disponível na página dos dados, não deixe de conferir para o entendimento completo sobre os métodos de análise e os dados.
Vamos explorar a coluna nametype, que indica o tipo de meteorito, havendo dois tipos possíveis:
- Valid: Tipo comum de meteorito;
- Relict: Meteorito degradado pelo clima da Terra.
Para verificar qual tipo possui mais dados vamos dividir o conjunto de dados entre as observações do conjunto do tipo Valid e as observações do tipo Relict.
# Separando por tipo de meteorito
df_valid = df[df['nametype'] == 'Valid']
df_relict = df[df['nametype'] == 'Relict']Vamos olhar nas dimensões de cada conjunto de dados gerados.
## (45641, 10)## (75, 10)Olha que bacana! Já é possível perceber que o número de meteoritos do tipo Valid é muito maior que os do tipo Relict. Agora, vamos entender a quantidade de massa média que cada um desses grupos apresenta.
# Agrupando para verificar a massa média por grupo
df_groupby_nametype = df.groupby('nametype')
df_groupby_nametype_massmean = df_groupby_nametype['mass'].mean()Vamos olhar o resultado do agrupamento.
## nametype
## Relict 0.121269
## Valid 13285.656127
## Name: mass, dtype: float64A massa média (apresentada em gramas) do grupo Valid é muito maior, o que pode ser explicado pela quantidade no conjunto de dados.
Para finalizar, vamos fazer a contagem dos tipos de meteoritos.
# Contagem da quantidade de tipos
df_groupedby_recclass = df.groupby('recclass')
df_groupedby_recclass_count = df_groupedby_recclass['recclass'].count()Por fim, façamos o filtro do conjunto de dados pela quantidade de massa .
# Filtragem (Maior que 500 gramas)
df_gt_mass_500 = df[df['mass'] > 500]
df_gt_mass_500.shape # Quantidade bem pequena## (7036, 10)É isso, o exemplo mostrou que conhecendo bem a estrutura e semântica dos dados e com os métodos apresentados no curso é possível extrair várias informações de um conjunto de dados.
3.4 Para saber mais
Não deixe de buscar mais informações! Abaixo alguns links que podem ser úteis.