1 Introdução
A análise de dados é uma das atividades mais interessantes da atualidade, com ela é possível monitorar o governo (por exemplo, Operação serenata), fazer empresas de sucesso e produtos que atendam a real necessidade de seus clientes, e o mais importante, comprovar a veracidade de informações recebida e saciar nossa curiosidade. Isto porque, com a quantidade de dados disponíveis, podemos literalmente, saber sobre tudo, aplicando técnicas de análise de dados. Portanto, este minicurso tem como objetivo apresentar, de forma introdutória, as principais tecnologias para analisar dados a partir das linguagens de programação R e Python.
1.1 Dados
Muito é dito sobre dados, que estes são abundantes e que estão em constante crescimento, porém, o que são dados?
Bem, esta pergunta possui diversas respostas, isso porque há várias definições para dados. Aqui iremos assumir que dados são:
“Qualquer coisa registrada com o propósito de posterior analise” - Dr. Rafael Santos.
Agora que sabemos a definição de dados, podemos deduzir que Big Data é um alto volume de dados. Não entraremos no mérito do que é, ou não, considerado Big Data. Caso queira ler mais sobre o assunto, recomendamos o artigo Big data: A survey publicado por Min Chen e colaboradores.
1.1.1 Tipos de dados
A tabela 1.1 foi feita com base no material de estatística da UFPR e o template utilizado foi retirado do livro-texto Claus O. Wilke.
| Tipo de variável | Exemplos | Escala apropriada | Descrição |
|---|---|---|---|
| Quantitativa/numérica contínua | 1.3, 5.7, 83, 1.5x10^-2 | Contínuas | Valores mensuráveis que assumem valores em um escala contínua (na reta real). Usualmente devem ser medida através de algum instrumento. Exemplo: peso (balança), tempo (relógio), e pressão arterial. |
| Quantitativa/numérica discreta | 1, 2, 3, 4 | Discretas | Características mensuráveis que podem assumir apenas um número finito ou infinito contável de valores e, assim, somente fazem sentido valores inteiros. Geralmente são o resultado de contagens. Exemplos: número de filhos, número de bactérias por litro de leite, número de cigarros fumados por dia. |
| Quantitativa/categóricas nominais | Cachorro, peixe | Discreto | Não possui ordenação dentre as categorias. Essas variáveis são também chamadas de factors. Exemplo: Sexo, cor dos olhos, doente/sadio. |
| Quantitativa/categóricas ordinais | Janeiro, Fevereiro | Discreto | Existe uma ordenação entre as categorias. Essas variáveis são também chamadas de ordered factors. Exemplo: escolaridade (1°, 2°, 3°), mês de observação (janeiro, fevereiro… dezembro). |
| Data ou tempo | Jan. 5 2018, 8:03am | Contínuo ou Discreto | Dia ou hora específicos. Também datas genéricas. Exemplo 29 de Fevereiro em anos não bissextos |
| Texto | The quick brown fox jumps over the lazy dog. | Nenhum, ou discreto | Texto normal e pode ser tratado como categórico se precisar. |
1.1.2 Formatos de dados
Como mencionado anteriormente, existem muitos dados disponíveis providos das mais diversas fontes e formatos. Boa parte dos desafios na análise de dados estão vinculados aos formatos nos quais os dados estão disponíveis, isso porque, dependendo do formato, existem diferentes etapas de organização que devem ser aplicadas.
“Os conjuntos de dados arrumados são todos iguais, mas todos os conjuntos de dados desorganizados são desorganizados à sua própria maneira.” - Hadley Wickham
Nos subtópicos abaixo, são descritos os principais formatos de dados e exemplos de cada um.
1.1.2.1 Dados estruturados
Este formato de dado segue a estrutura de linhas e colunas (retangular). São geralmente encontrados em banco de dados, Excel (.xls) e valores separados por vírgulas (do inglês Comma-separated values) (.csv)
1.1.2.2 Dados Semiestruturados
São dados que possuem uma organização clara, porém, não seguem o padrão de linha e coluna. Geralmente são aqueles formatos que recebemos em requisições via API (do inglês "Application Programming Interface) Web, por exemplo, JSON, XML e HTML.
1.1.2.3 Dados não estruturados
São aqueles que não conseguimos identificar uma organização clara, geralmente, são arquivos com forte teor textual, por exemplo, e-mail, tweets, PDF, imagens, vídeos, entre outros.
Lembrando que, nem todo dado desorganizado é não estruturado.
1.2 O que é análise de dados?
Segundo John W. Tukey, grande parte da análise de dados é inferencial, ou seja, o ato de extrair informações de uma amostra em relação ao conjunto todo. É interessante ressaltar que, análise de dados não é um conceito novo, a definição de Tukey foi publicada em 1962, no artigo The Future of Data Analysis.
Inferência estatística é um ramo da Estatística cujo objetivo é fazer afirmações a partir de um conjunto de valores representativos (amostra) sobre um universo (população). - Wikipedia
Buscando por mais definições, a Wikipedia descreve análise de dados como o processo de observação, limpeza, transformação e modelagem de dados. Com o objetivo de extrair informações de dados não tratados.
1.2.1 O que faz um analista de dados?
O artigo “Data Engineer, Data Analyst, Data Scientist - What’s the Difference ?” publicado pelo dataquest, define o analista de dados como um agregador para a companhia, que obtém respostas através de dados. Dessa forma, ajudando na tomada de decisão da empresa. De acordo com o artigo do dataquest, um analista de dados é responsável pelas seguintes áreas:
- Limpeza e organização de dados;
- Uso de estatística para ter uma visão geral dos dados;
- Análise de tendências encontradas nos dados;
- Criação de gráficos e dashboards para ajudar na interpretação e tomada de decisão da empresa;
- Apresentação dos resultados obtidos para os clientes.
Resumindo essas tarefas, o analista deve possuir habilidades de limpeza, manipulação e visualização dos dados, entender do negócio e saber transferir as informações geradas de suas análises para diferentes tipos clientes, com ou sem domínio técnico.
1.2.2 Quais são as diferenças entre analista e cientista de dados?
Tanto se fala de analista e cientista de dados, mas afinal, qual é a diferença?👩💻
Segundo a revista Harvard Business Review, cientista de dados é considerada a profissão mais sexy do século 21.
De acordo com Josh Wills, um cientista de dados é melhor em estatística do que qualquer engenheiro de software e melhor em engenharia de software do que qualquer estatístico. Um cientista de dados possui todas as habilidades de um analista, mas, em essência contém um domínio maior em estatística, matemática e Machine Learning. Em busca de um compilado de definições, formulamos nossa resposta com base nesses sites:
A definição que escolhemos foi a do site kdnuggets: “O analista de dados é como o Sherlock Holmes 🔍 do time de ciência de dados”. Ainda em sua definição, “o analista busca resposta para o time e para o negócio. Por outro lado o cientista de dados, cria modelos estatísticos de aprendizado de máquina, visualizações mais elaboradas e gera novas perguntas em relação aos dados”.
Fiquem à vontade para adicionar mais diferenças, veja como contribuir no README do projeto.
1.2.3 Processos da análise de dados
Agora que sabemos o que faz um analista de dados, é necessário entender as etapas do processo de análise de dados. Na Figura 1.1 é apresentado um fluxograma sequencial das etapas do processo.
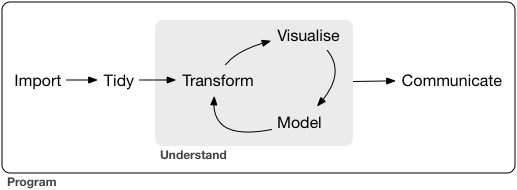
Figure 1.1: Etapas do processo de análise de dados - Fonte: Wickham and Grolemund (2017)
A primeira etapa (Import) consiste em fazer a leitura aos dados, independentemente do formato do arquivo (.csv, .kml, .json). Após a leitura dos dados, é necessário organizar, estruturar os dados e corrigir possíveis erros tornando os dados tidy. O termo tidy refere-se a nova estrutura do conjunto de dados, onde cada coluna é um atributo e cada linha é uma observação (Wickham and Grolemund 2017). A seguir é apresentado um exemplo sobre a linguagem R, com 3 atributos (nome, idade e escolaridade) e 3 observações:
library(knitr)
escola <- tibble::tibble(nome=c("Joao", "Maria","Helena"),
idade=c(14, 15, 21),
escolaridade=c("EF", "EM", "Graduacao" ))
knitr::kable(escola)| nome | idade | escolaridade |
|---|---|---|
| Joao | 14 | EF |
| Maria | 15 | EM |
| Helena | 21 | Graduacao |
Com o dado no formato tidy, facilmente pode-se observar que João tem 14 anos e está no ensino fundamental.
A etapa de Transform é composta pela adição de novos atributos com base no conjunto de dados primário, por exemplo, a média da idade dos alunos. Esta etapa tem como objetivo gerar questionamentos sobre o conjunto de dados e tentar respondê-las através da manipulação dos dados. No código em R abaixo é apresentado um exemplo de transformação que pode ser realizada, onde um novo atributo é gerado ao extrair o dia da smeana de uma determinada data.
## [1] qui
## Levels: dom < seg < ter < qua < qui < sex < sábNo exemplo acima, estamos usando o pacote lubridate para descobrir o dia da semana da data 11 de outubro de 2018.
A etapa Visualise consiste em produzir representações dos dados que permitam uma análise visual das informações, como por exemplo, a utilização de gráficos. Visualizar o conjunto de dados, pode gerar novos conhecimentos, questionamentos e respostas. Segundo Wilke (2019), a visualização de dados, é a parte arte e a parte ciência na área de ciência de dados, portanto, a visualização precisa estar correta e agradável para interpretá-la.
TIL: visualisation ou visualization possuem o mesmo significado, mas, na Europa é com “s” e na América com “z”.
Na etapa Models são geradas abstrações ou modelos a partir da visualização
Segundo Wickham and Grolemund (2017), Models são ferramentas complementares de visualização. Para Schutt and OŃeil (2013), realizar a análise exploratória de dados (EDA) é a etapa fundamental para a criação de um modelo. Communicate é a última etapa do processo, sendo fundamental para o analista transmitir as informações obtidas através da análise dos dados, para clientes técnicos e não técnicos. Para isso, o analista apoia-se nos gráficos e modelos criados, por isso, é necessário que os gráficos possuam, pelo menos, uma estética agravél e de fácil interpretação.
Nos próximos capítulos é apresentado com detalhes quais pacotes e bibliotecas podem ser aplicados em cada etapa do processo de análise de dados.
1.3 Contribuição
Este material está em constante mudança e todas as recomendações e melhorias são bem-vindas. Fique à vontade para adicionar mais conteúdo, instruções de colaboração no README.